这是本人在学习TensorFlow实战一书时所记录下来的一些内容。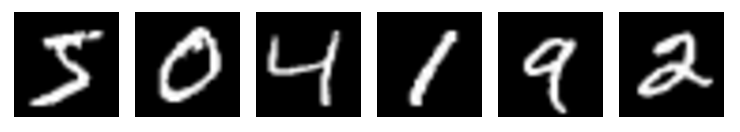
MNIST数据集
MNIST(Mixed National Institute of Standards and Technology database)是一个非常简单的机器视觉数据集,如上图所示,它由几万张28像素x28像素的手写数字图片组成,这些图片只包含灰度值信息(channel=1)。
我们所需要做的任务就是对这些手写数字的图片进行分类,转成0~9一共10类。
首先对MNIST数据进行加载,TensorFlow为我们提供了一个方便的封装,可以直接加载MNIST数据成我们期望的格式。
在Jupyter上运行代码:
结果显示为:
数据集成功下载获得,并打印出mnist的训练集中有55000张图像,784维的特征,测试集有10000张图像,验证集有5000张图像。
注:
1) 图像是28像素x28像素大小的灰度图片,即空白部分全部为0,有笔迹的地方根据颜色深浅有0到1之间的取值。
2) 每个样本有784维的特征,来自于将28x28个像素点展开成一维的结果(28x28=784)。
3) 此处简化了问题,丢弃图像的空间结构的信息,将图片按同样的顺序展开至1维向量即可。
4) 训练数据的特征是一个55000x784的Tensor,第一个维度是图片的编号,第二个维度是图片中像素点的编号。同时训练的数据Label是一个55000x10的Tensor。测试集、验证集同样道理。
5) 读取数据时,对10个种类进行了one-hot编码,Label是一个10维的向量,只有1个值为1,其余为0。比如数字0,对应的Label就是[1,0,0,0,0,0,0,0,0,0],数字5对应的Label就是[0,0,0,0,0,1,0,0,0,0],数字n就代表对应位置的值为1。
Softmax Regression
数据准备好后,我们采用的是一个叫Softmax Regression的算法来训练手写数字识别的分类模型。
数据集的数字都是0~9之间的,所以一共有10个类别。
当模型对一张图片进行预测时,Softmax Regression会对每一种类别估算一个概率,比如预测是数字3的概率为80%,是数字5的概率为5%,最后取概率最大的那个数字为模型的输出结果。
$i$代表第$i$类,$j$代表一张图片的第$j$个像素,$b_i$是bias。$$feature_i = \sum_j W_ix_j + b_i$$
接下来对所有特征计算Softmax,即计算一个exp函数,然后再进行标准化(让所有类别输出的概率值之和为1)。
$$softmax(x) = normalize(exp(x))$$
其中判定为第$i$类的概率可由下面公式得到:
$$softmax(x)_i = \frac{exp(x_i)}{\sum_jexp(x_j)}$$
整个Softmax Regression的流程如下图所示:
转换为公式的话,如下图所示,将元素相乘变成矩阵乘法: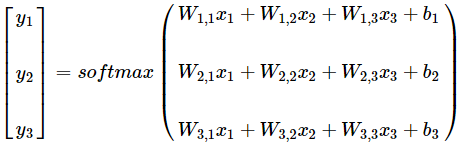
即: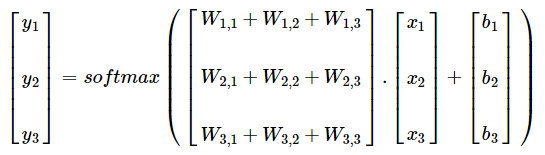
上述矩阵表达写成公式的话,就可用下面一行表达:
$$y = softmax(Wx + b)$$
TensorFlow实现
|
|
|
|
注:
1) 存储数据的tensor一旦使用就会消失,但Variable在模型训练迭代中是持久化的,可长期存在并在每轮迭代中被更新。
2) 这里全部初始化为0,因为模型训练时会自动学习合适的值,对这个简单模型来说初始值不太重要。
3) 但对于复杂的卷积网络、循环网络或较深的全连接网络,初始化得方法比较重要。
|
|
注:
1) 损失函数越小,代表模型的分类结果与真实值的偏差越小,即模型越精确。
2) 训练的目的是不断将这个损失减小,直到达到一个全局最优或者局部最优解。
3) 对多分类问题,通常使用cross-entropy交叉信息熵来作为损失函数。
|
|
|
|
|
|
注:argmax获取的是最大值所在位置索引,所以一个是y中概率最大的那类所在位置索引,另一个是真实值y_中最大(即值为1)的位置索引,之后将两者进行equal比较,相等则为true,反之false,最后获得correct_prediction的bool矩阵。
|
|
最后的预测精度约为92% 。
附上程序:https://github.com/asdfv1929/TensorFlowInActionLearning (TensorFlow实现Softmax Regression识别手写数字)

