本篇主要记录的是关于小说网的简单爬取,并将内容保存至txt文件中。
前期准备
准备工作的话,一方面Python语言,另一方面就是几个Python库的使用:requests、bs4等。
关于这些库的具体用法,我这边就不描述了,详细的内容可见官方文档或某些博客:
requests:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
bs4:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
小说网链接:http://www.quanshuwang.com/list/1_1.html
小说模型
我是定义了一个小说类模型,用来存储或操作一篇小说的相关信息。
首先是,通过小说的一些数据信息对小说进行初始化:
之后,我简单定义了一个获取网页源码的方法:
接着便是获取该小说所有章节的标题及章节链接:
最后便是通过章节链接,去访问该章节对应的小说内容,当然,里面还包括了将内容存入本地txt:
其中,里面有调用了写入文本的方法:
所有小说信息
在这边,我主要是获取链接页面中,所有小说的基本信息,例如小说名、作者、封面图片链接、内容简介、跳转链接等。
首先便是,基本的网页源码读取:
接着是获取该页面上所有小说的基本信息:小说名、作者、封面链接、内容描述、跳转链接,返回信息列表
这边是小说信息写入csv文件的方法:
之后便是获取小说跳转至目录的链接,并将该链接也添加至数据信息列表,并返回:
最后便是实例化小说对象,然后获取所有章节链接,之后遍历访问它的小说内容:
调用运行
最后就是在main里调用运行即可:
运行显示: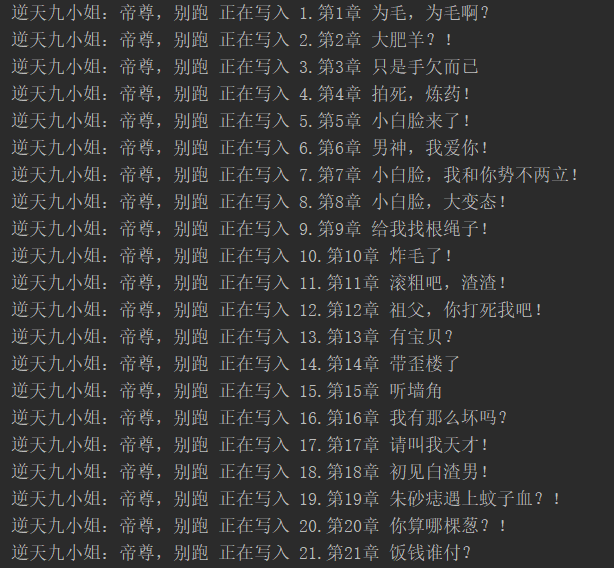
小说下载: