| Name | DESC |
|---|---|
| TITLE | Foreground Object Sensing for Saliency Detection |
| AUTHOR | Hengliang Zhu, Bin Sheng, Xiao Lin, Yangyang Hao, Lizhuang Ma |
| PBYEAR | 2016 |
| TRANSLATION | asdfv1929 |
| TIME | 2018.3 |
摘要
许多先进的显著性检测算法都依赖于边界先验(boundary prior),但是这些算法只是简单地将图像周围的边界视为背景区域。在这里,我们提出一种快速有效的显著目标检测算法。首先提出一个新的方法,通过使用Harris Corner的凸包(convex hull)来近似定位前景目标。在此基础上,我们将不同区域的显著值划分为两部分,生成对应的贴图(cue maps)(前景和背景),并将其合并为凸包先验图(a convex hull prior map)。然后基于到凸包中心的距离提出一个新的先验来代替之前的中心先验。最后,将凸包先验图和凸包中心偏差(center-biased)图组合为显著图,然后对显著图进行优化以获得最终结果。通过与18个现有算法进行比较,在几个数据集上进行测试,本算法在精度和查全率(precision and recall)方面均表现良好。
CCS概念:计算方法 –> 兴趣点和显著区域检测
关键字:前景目标;Harris Corner;凸包;显著图
引言
在对生物(人类)视觉系统的信息处理机制进行研究之后,近年来关于视觉显著性检测的工作迅速发展增加,并成功地应用到众多计算机视觉应用中,如图像分割[34],图像压缩[13, 23],图像缩放[29],图像检索[8, 35]和图像质量评估[46]。“视觉显著性”的目标是找到图像中的丰富信息区域(abundant information regions),其中的显著区域和非显著区域在感知上是可区分的。
从心理学角度[22]来看,显著性检测可以分为自下而上(数据驱动)方法[7, 12, 15, 32, 39, 45, 48]和自上而下(目标驱动)方法[20, 27, 47]。与后者利用图像的高级先验知识相比,前者利用图像的低级特征(例如,颜色、位置和纹理)来检测显著性区域。有了这些原始特征,在之前的工作[1, 18, 28, 37, 48]中,研究者提出了诸如中心先验(center prior)、对比度先验(contrast prior)和边界先验(boundary prior)等先验假设,以提高显著目标检测的准确性。在本文中,我们主要关注自下而上的显著性检测方法。
近年来,显著性检测通常采用图像边界先验,它假定图像的窄边界是非显著性区域。换句话说,图像边界倾向于被视为是背景。有许多先进的算法依赖于边界先验[19, 41, 45, 48],并且获得了更好的性能。然而,这些工作的一个局限性便是显著目标可能会轻微触碰到图像边缘。换句话说,检测到的显著目标在图像边界区域是不完整的。
为解决这个问题,我们提出了一个简单有效的显著区域检测算法(工作流程见图1)。首先,基于角点检测算法(Harris Corner[40]),提出一个新的前景目标定位算法,该算法使用两个凸包交叉区域(intersections)来近似定位前景目标。交叉区域排除了更多分散的背景,并集中在显著目标的周围。其次,通过结合全局对比度线索(global contrast cues),我们引入了一个新的区域(图像块)显著性计算阶段(详见Section 3)。我们将一个区域的显著值划分为两部分:一部分位于凸包内部(显著区域,可能包含一些背景),另一部分位于凸包外部(背景区域)。它们被用于生成两个贴图(cue maps)(前景和背景),这两个贴图之后组合成凸包先验图。最后,优化得到显著图。
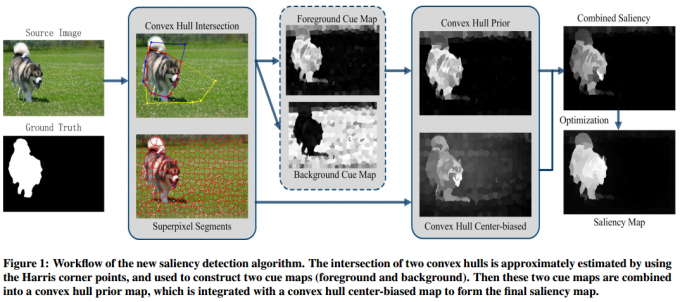
文章剩余部分安排如下。Section 2回顾了相关工作。所提出的显著性计算方法的细节在Section 3和Section 4中给出。Section 5展示实验结果和讨论。总结在Section 6中给出。
相关工作
[4, 5]中提供了显著性检测的详细总结。跟踪眼球移动的固定预测模型[3, 11, 14, 16]主要是利用到物理设备。相反,这项工作是基于图像处理的研究。本节中,我们简要回顾下主要的显著性检测算法,还有它们之间的区别。
关于显著性检测的开创性研究是由Itti等人所进行的[17],他们将像素的显著值定义为局部中心-环绕差异(local center-surround difference)。该检测基于多尺寸的图像特征,包括颜色、强度和方向。
之后,包括局部或全局对比的对比先验(contrast prior)被广泛用于检测显著目标和区域。例如,Ma等人[28]提出了基于局部对比的显著区域检测方法,该方法以单一尺寸运行。Cheng等人[7]在显著性计算时考虑了全局对比。Perazzi等人[32]使用唯一性和空间分布来计算显著图。Goferman等人[12]提出了一个情景感知(context-aware)显著性检测模型。Achanta等人[1]提出了一种多尺寸方法来生成显著图。所有这些方法都利用图像的低级特征来表征(characterize )视觉显著性。另外,一些工作[19, 20, 27]以机器学习的方式使用了原始特征,并且产生了更优的结果。
最近,边界先验被应用于检测显著区域,其中图像边界区域被简单地视为背景。直观地说,显著区域与图像边界的连接要比背景中的显著区域少得多。Wei等人[41]提出了一种测地(geodesic)显著性方法,它将背景视为线索提示(cues)而不是显著目标。Chuan Yang等人[45]提出了一种基于图形的流形(manifold)排序方法,它使用图像背景区域作为查询。W.Zhu等人[48]提出了一种称为边界连通性的显著性度量,它利用图像块与图像边界之间的空间关系。X.Li等人[24]通过使用背景模板来测量密集和稀疏重构建错误(dense and sparse reconstruction errors)的显著性。为了利用区域与其邻居的内在联系,Q.Yao等人[33]将显著目标检测视为细胞自动演化过程。但从另一个角度来看,显著性检测的另一个关键点是前景对象的位置。Harris点的凸包被广泛用于近似估计前景区域。例如,可以使用基于凸包的低级提示来估计显著性[42, 43]。R.Liu等人[26]采用Harris算子来获得候选前景和背景。Pan等人[31]通过使用图像抠像模型(image matting model)提出了一种边缘保留滤波(edge preserving filter)方法。
然而,边界先验算法只是将图像边界视为背景,而基于凸包的算法可能包含更多非显著区域。为了克服这些困难,我们提出了用于显著性检测的前景目标感知度量(foreground object sensing measure)。
前景目标感知
算法步骤如下。首先,我们提出一种新方法来近似定位前景目标。之后,生成两个显著贴图(前景和背景),并最终以简单的方式将其集成到凸包先验图中。然后,我们提出一种基于凸包中心偏差的加权全局对比算法。这些详细内容分别在Section 3.1-3.3中讨论。
目标位置估计
根据视觉注意机制,许多研究均表明,显著区域有一个明显不同的外观,并可以与其周围区分开来。受这一原则启发,我们使用图像的特征点来获取凸包,然后大致定位前景目标。
现有许多特征点检测器,如scale-invariant feature transform(SIFT),speeded-up robust features(SURF)和Harris。考虑到计算复杂度低,我们利用Harris Corner来粗略检测显著目标的特征点。在实验中,我们发现Harris角点只用于计算显著区域的凸包是不恰当的,因为凸包区域可能包含了太多的背景。为了更准确地定位前景目标,我们需要进一步消除凸包区域中的背景影响。
通常,显著目标是图像中信息最丰富的区域,其边缘或轮廓在像素上的强度或颜色是不连续的。然而,在频域(frequency domain)中,亮度变化可能对应着高频分量。因此,为了抑制属于背景的一些高频成分,我们使用低通滤波器来平滑原始图像,例如平均滤波器和高斯低通滤波器。然后我们再次使用Harris算子来检测滤波图像中的角点并获得相应的凸包。两个凸包区域分别表示为$R_1$和$R_2$(图2(b),图2(c)),然后确定它们的交点。我们将这个交叉区域定义为
$$
\begin{equation}
R_F = R_1 \cap R_2
\end{equation}
$$
图2显示了使用凸包的前景目标区域的定位。交叉区域(红色多边形)排除了更多分散的背景(图2(d)),并且可以近似视为前景目标区域。此外,图像的背景($R_F$外部)区域被表示为$R_B$。在我们的实验中,我们使用平均滤波器,将其大小设置为35。

显著性计算
在计算显著图之前,我们先使用简单线性迭代聚类算法(SLIC)[2]将原始图像分割为超像素(superpixels)区域,这样可以有效地生成紧凑和均匀的超像素。在我们的实验中,我们将图像中超像素的数量设置为300。超像素区域集合表示为$X = {r_1,r_2,…,r_N}$,其对应地显著值为$V = {v_1,v_2,…,v_N}$,其中$v_i$是超像素区域$r_i$的显著值,$N$是超像素的数量。
基于前景目标的位置,我们将每个超像素的显著值分为两个部分:一部分在凸包内部,一部分在凸包外部,分别表示为$SF_i$和$SB_i$。然后我们通过连接所有相邻的超像素$r_i$和$r_j$来构造一个无向图,图中边的权重是CIELab颜色空间中超像素的平均颜色之间的欧氏距离。因此,基于该图,我们使用测地距离(geodesic distance)来计算两个超像素区域之间的差异,这很容易通过最短路径算法计算得到。
因此,我们将超像素区域的$SF_i$定义为与$R_F$中的所有区域相比测地距离的总和。所以,$SF_i$写为:
$$
\begin{equation}
SF_i = \sum_{j=1}^{N_1}shtDist(c_i, c_j), r_j \in R_F
\end{equation}
$$
其中$shtDist(c_i, c_j)$是两区域$r_i$和$r_j$之间的最短路径;$c_i$和$c_j$分别是CIELab颜色空间中超像素$r_i$和$r_j$的平均颜色,区域$r_j$属于$R_F$;$N_1$是凸包内超像素的总共数量。样例如图3(b)所示。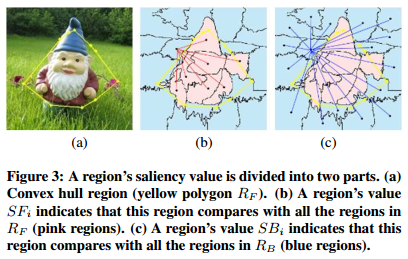
与$SF_i$一样,我们将超像素区域的$SB_i$定义为与$R_B$中所有区域相比的测地距离的总和。因此,$SB_i$由下式计算得到:
$$
\begin{equation}
SB_i = \sum_{j=1}^{N_2}shtDist(c_i, c_j), r_j \in R_B
\end{equation}
$$
其中$r_j$属于$R_B$;$N_2$是凸包外部超像素的总数,如图3(c)所示。注意,$N = N_1 + N_2$。
前景贴图(Foreground Cue Map) 显著区域通常是重要且吸引人的地方[5],并且通常在与周围环境中比较突出。因此,$R_F$中超像素区域的显著值要高于$R_B$中。对于给定区域$r_i$,如果它在凸包内,则$SF_i$小于$SB_i$,所以$SB_i / SF_i$高;如果它位于凸包外部,则$SF_i$大于$SB_i$,所以$SB_i / SF_i$低。
鉴于这个事实,我们使用凸包区域构造前景贴图。图像中每个超像素区域的显著值定义为:
$$
\begin{equation}
FC_i = SB_i / SF_i
\end{equation}
$$
上述等式确保前景$R_F$中的区域的显著值高于背景$R_B$中的显著值。图4(b)展示了前景贴图的一些结果。显然,整个前景目标区域突出显示了,并且具有比凸包外部区域(背景)更大的值。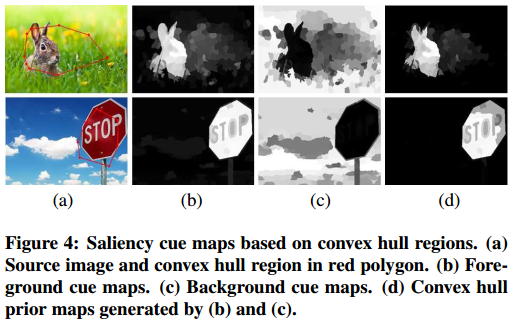
背景贴图(Background Cue Map) 与前景贴图相反,我们可以构造对应的背景贴图。背景$R_B$中的超像素区域拥有比前景区域超像素更大的显著值。背景贴图定义为:
$$
\begin{equation}
BC_i = SF_i / SB_i
\end{equation}
$$
其中$BC_i$是图像中一个区域的显著值。如图4(c)所示,我们可以看到背景区域几乎都是突出显示的。
凸包先验图(Convex Hull Prior Map) 前景贴图不够均匀,是因为一些背景区域具有高显著性(图4(b)),但背景贴图更突出地显示了非显著区域(图4(c))。因此,我们提出了一种算法将这两个贴图组合成如下的凸包先验图: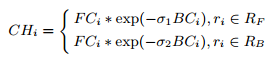
其中,$r_i$ 是超像素区域。事实上,背景贴图对背景有很大的影响,所以它的效果由参数 $\sigma_1$ 和 $\sigma_2$ 来平衡。当$r_i \in R_F$,我们分配给$\sigma_1$一个较小值;当$r_i \in R_B$,我们分配给$\sigma_2$一个较大值。注意,我们在实验中是将$\sigma_1$和$\sigma_2$设为常数值。根据经验,我们设置$\sigma_1 = 2.5$,$\sigma_2 = 6$。
此外,凸包先验图被归一化到范围[0, 1]内。根据一些视觉上的比较(图4(d)),背景区域明显减小。
凸包中心偏差算法(Convex hull center-biased algorithm)
视觉注意研究显示人类倾向于将焦点集中在图像的中心区域[38]。有一些使用中心先验的显著性模型[18, 44],认为靠近图像中心的区域可能是一个显著对象。换句话说,背景区域往往远离图像中心。然而,在许多情况下,中心先验模型可能无效并且错过了一些显著区域。因此,我们充分利用凸包中心偏差作为全局区域对比的加权因子[7]。假设$\mu(x_c, y_c)$表示凸包的中心,那么我们算法中区域的全局对比就写为:
$$
\begin{equation}
G(r_i) = \sum_{j=1}^N \phi(r_i, r_j)\Vert c_i - c_j \Vert_2 \psi(r_i, \mu)
\end{equation}
$$
其中$\phi(r_i, r_j)$是高斯权重函数,将其设置为$exp(-d(r_i, r_j)/(2\delta_1^2))$,表示$r_i$和$r_j$这两个区域中心之间的空间距离;$\psi(r_i, \mu)$是权重因子,将其设置为$exp(-d(r_i, \mu)/(2\delta_2^2))$;$d(r_i, \mu)$表示区域$r_i$和凸包的中心之间的欧氏距离。根据经验,$\delta_1$和$\delta_2$在我们的实验中分别设定为0.4和0.2。如图5所示,当前景目标不在图像中心时,第二和第三行出现了一些情况,图5(c)展示了我们算法的结果。
整合、优化
凸包先验图和凸包中心偏差图互为补充。如图5(b)所示,我们可以看到前景目标明显突出显示,但仍有一些背景区域与显著目标没有明显分离开。
与前景目标相比,显著图中的背景区域被弱化(图5(c))。因此,我们可以利用这两个显著图并以简单的方式将它们组合到最终的显著图中去。定义组合后的显著图为:
$$
\begin{equation}
S_i = CH_i * G_i
\end{equation}
$$
如组合显著图所示(图5(d)),我们可以看到,背景区域被上面等式给完全消除掉了。为了进一步生成均匀突出的显著映射,我们使用[48]中报告的优化函数来改进我们的结果。使用不同的系数,优化函数被重写为:
$$
\begin{equation}
\sum_{i=1}^N B_iv_i^2 + \sum_{i=1}^N S_i(1-v_i)^2 + \sum_{i, j}\phi(r_i, r_j)(v_i, v_j)^2
\end{equation}
$$
其中$v_i$是超像素的显著值,$B_i$由等式5和等式8决定,因为$B_i = (1 - S_i)BC_i$。系数$B_i$和$S_i$分别控制背景和前景显著值。第三项是平滑约束,它控制从前景到背景的平滑过渡(smooth transition)。图5(e)中展示了一些示例,显然,优化后显著目标很好地突出显示。
实验
为了测试我们算法的性能,我们进行了两种实验:(1)性能评估,包括精确度和召回率(PR)曲线,F-度量和平均绝对误差(MAE),它们按照[15, 32]中描述的内容计算得到;(2)对所提出算法中对最终显著图做出贡献的每个分量做一些评估。
我们将我们的算法(表示为FOS)与现有的18种先进的显著性检测算法(包括有IT[17], FT[15], SR[16], CA[12], SF[32], GS[41], GC[10], HS[44], PCA[30], RC[7], SVO[6], LMLC[43], GMR[45], DSR[24], HDCT[21], wCO[48], BL[33], 和BSCA[39])进行了比较。这些算法的结果是使用相应作者的公开可用源代码或demo来运行得到的。实验是在6个基准数据集(ASD[15], MSRA5000[27], THUS10000[9], ECSSD[44], Pascal-S[25] and SED2[36])上测试进行的。
定量评估
我们选择两种客观的评估方法(固定阈值和自适应阈值)来评估所有显著性检测算法。首先,对于每个显著图,使用位于[0, 255]范围内的增量为1的固定阈值来生成二值图。然后,我们使用精度和召回率的结果来与真实图进行比较。PR(precision-recall)曲线的结果如图6(a)和6(b)所示,其从上行到下行的结果分别为MSRA5000, THUS10000, ECSSD和Pascal-S。我们的算法在精度和召回率方面要优于其他算法。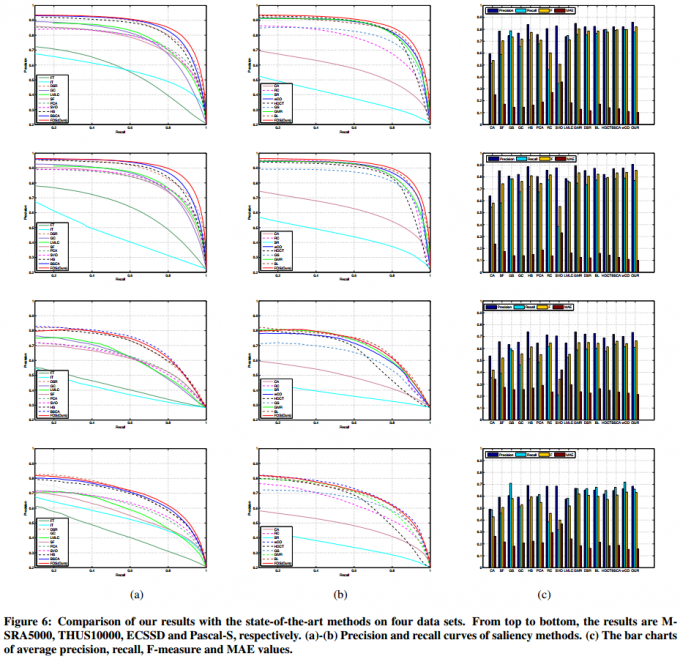
其次,我们还估计每种算法的平均精确度、召回率、F-度量和MAE值。根据文献[15]中的配置,我们设置自适应阈值
$T = 2*Mean(S) $ ($S$是显著映射),F-度量的表达式为:
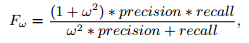
其中我们设置$w^2 = 0.3$。这些值的结果展示在图6(c)条形图中。总之,与其他18种算法相比,我们的算法取得了良好的效果,特别是在F-度量和MAE方面。
为了准确评估这些显著性算法的性能,我们用5个数据集上的12个代表性算法提供了F-度量和MAE的定量结果(表1)。我们可以看到,我们的算法明显优于其他现有算法。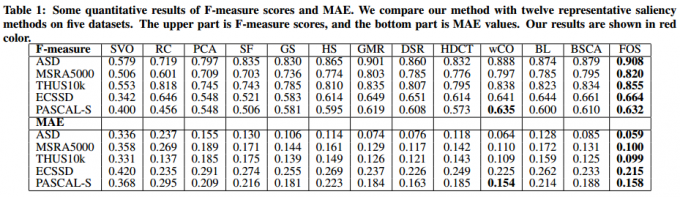
定性评估
我们在图9中提供了本算法和其他十个先进的算法的显著映射。从结果中我们可以看出,我们的算法生成的显著映射可以清楚地将显著目标与背景分隔开。当图像具有复杂的背景结构时,我们的算法仍然以较少的噪声背景产生了有利的结果。例如,在第四行和第五行中,我们的显著图可以统一突出显示图象的前景目标,但其他算法无法从分散背景中提取突出目标。另外,当显著目标与背景具有相似的外观时,我们的算法能够精确地检测出显著区域,如第一行和第三行所示。通常,我们的算法可以生成具有突出显示显著目标的显著图,并有效地抑制背景区域(图9)。
算法分析
为了证明我们所提出的算法的有效性,我们还评估了算法中每个分量的性能。每个分量都有助于最终的结果,如前景贴图,凸包先验图,凸包中心偏差图,组合显著图和最终显著图。图7显示了ASD(MSRA 1000)数据集上我们算法的每个单独分量的精度和召回率。很明显,凸包先验图和组合显著图也可以生成高精度结果。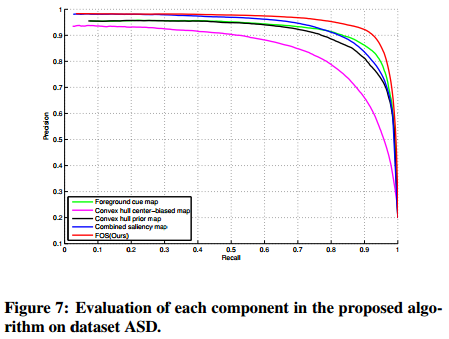
限制
我们还展示了在数据集SED2(100张图像)上我们算法和其他显著性检测器的实验结果。SED2包含有多个显著目标,这对显著性检测来说是一个巨大的挑战。结果如图8所示。我们可以看到,我们的算法在数据集SED2上的表现并不是最好的。如PR曲线(图8)所示,随着召回率的增加,精度不断下降。直观地说,当图像包含多个具有非常大空间距离的显著目标时,我们的算法在检测这些显著目标时存在一些限制,特别是在精度方面。由于图像中多个目标的大小和位置都是非常不同和多样化的,并且几乎不用我们算法中使用的一个凸包进行覆盖,如图8中的失败情况所示。也许我们可以使用多个凸包来提高多目标检测的算法能力。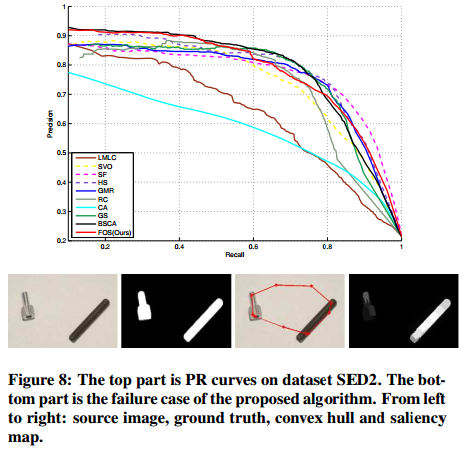
时间复杂度
我们在ASD数据集上比较了FOS和最具代表性或最新的算法。表2列出了每种算法的平均运行时间。我们使用相应作者的公开源代码来运行它们的算法,并且我们的算法是基于Matlab R2013a实现的。所有的实验都是在Intel Core i5-3470 CPU@3.2Hz 4G RAM、windows 8的PC上运行的。很明显,我们算法的计算复杂度较低。
总结
本文中,我们通过前景目标感知提出了一种高效的显著性区域检测算法。为了准确定位前景目标,我们首先引入了一种新方法来近似估计显著目标的位置,这可以消除大部分背景信息。我们还提出了一个凸包中心偏差算法来提高对比前景区域并削弱背景影响。大量的实验结果表明,新算法可以生成高质量的均匀显著图,并均匀地突出显著区域。将来,我们将改进用于检测多个显著目标的算法。
文献
[1] R. Achanta, F. Estrada, P. Wils, and S. Süsstrunk. Salient region detection and segmentation. Computer Vision Systems, pages 66–75, 2008.
[2] R. Achanta, A. Shaji, K. Smith, A. Lucchi, P. Fua, and S. Süsstrunk. Slic superpixels compared to state-of-the-art superpixel methods. IEEE Transactions on Pattern Analysis and Machine Intelligence, 34(11):2274–2282, Nov 2012.
[3] B. Ali, D. N. Sihite, and I. Laurent. Quantitative analysis of human-model agreement in visual saliency modeling: a comparative study. IEEE Transactions on Image Processing, 22(1):55–69, 2013.
[4] A. Borji, M.-M. Cheng, H. Jiang, and J. Li. Salient object detection: A survey. Eprint Arxiv, 16(7):3118, 2014.
[5] A. Borji, D. N. Sihite, and L. Itti. Salient object detection: A benchmark. In European Conference on Computer Vision (ECCV), 2012.
[6] K.-Y. Chang, T.-L. Liu, H.-T. Chen, and S.-H. Lai. Fusing generic objectness and visual saliency for salient object detection. In International Conference on Computer Vision (ICCV), pages 914–921, 2011.
[7] M. Cheng, N. J. Mitra, X. Huang, P. H. S. Torr, and S. Hu. Global contrast based salient region detection. In Computer Vision and Pattern Recognition (CVPR), pages 409–416, 2011.
[8] M.-M. Cheng, N. J. Mitra, X. Huang, and S.-M. Hu. Salientshape: Group saliency in image collections. The Visual Computer, pages 1–10, 2013.
[9] M. M. Cheng, N. J. Mitra, X. Huang, P. H. S. Torr, and S. M. Hu. Salient object detection and segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 37(3):1, 2011.
[10] M.-M. Cheng, J. Warrell, W.-Y. Lin, S. Zheng, V. Vineet, and N. Crook. Efficient salient region detection with soft image abstraction. In International Conference on Computer Vision (ICCV), pages 1529–1536, 2013.
[11] D. Gao, V. Mahadevan, and N. Vasconcelos. The discriminant center-surround hypothesis for bottom-up saliency. Advances in Neural Information Processing Systems (NIPS), 20:497–504, 2007.
[12] S. Goferman, L. Zelnik-Manor, and A. Tal. Context-aware saliency detection. In Computer Vision and Pattern Recognition (CVPR), pages 2376–2383, 2010.
[13] C. Guo and L. Zhang. A novel multiresolution spatiotemporal saliency detection model and its applications in image and video compression. IEEE Transactions on Image Processing, 19(1):185–198, 2010.
[14] J. Harel, C. Koch, and P. Perona. Graph-based visual saliency. In Annual Conference on Neural Information Processing Systems (NIPS), pages 545–552, 2007.
[15] S. Hemami, F. Estrada, and S. Susstrunk. Frequency-tuned salient region detection. In Computer Vision and Pattern Recognition (CVPR), pages 1597–1604, 2009.
[16] X. Hou and L. Zhang. Saliency detection: A spectral residual approach. In Computer Vision and Pattern Recognition (CVPR), pages 1–8, 2007.
[17] L. Itti, C. Koch, and E. Niebur. A model of saliency-based visual attention for rapid scene analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence, 20(11):1254–1259, 1998.
[18] H. Jiang, J. Wang, Z. Yuan, T. Liu, N. Zheng, and S. Li. Automatic salient object segmentation based on context and shape prior. In British Machine Vision Conference (BMVC), pages 1–12, 2011.
[19] H. Jiang, J. Wang, Z. Yuan, Y. Wu, N. Zheng, and S. Li. Salient object detection: A discriminative regional feature integration approach. In Computer Vision and Pattern Recognition (CVPR), pages 2083–2090, June 2013.
[20] T. Judd, K. Ehinger, F. Durand, and A. Torralba. Learning to predict where humans look. In International Conference on Computer Vision, 2009.
[21] J. Kim, D. Han, Y.-W. Tai, and J. Kim. Salient region detection via high-dimensional color transform. In Computer Vision and Pattern Recognition (CVPR), pages 883–890, June 2014.
[22] C. Koch and S. Ullman. Shifts in selective visual attention: Towards the underlying neural circuitry. In Matters of Intelligence, volume 188, pages 115–141. 1987.
[23] I. Laurent. Automatic foveation for video compression using a neurobiological model of visual attention. IEEE Transactions on Image Processing, 13(10):1304–18, 2004.
[24] X. Li, H. Lu, L. Zhang, X. Ruan, and M.-H. Yang. Saliency detection via dense and sparse reconstruction. In International Conference on Computer Vision (ICCV), pages 2976–2983, Dec 2013.
[25] Y. Li, X. Hou, C. Koch, J. M. Rehg, and A. L. Yuille. The secrets of salient object segmentation. In Computer Vision and Pattern Recognition (CVPR), pages 280–287, 2014.
[26] R. Liu, J. Cao, Z. Lin, and S. Shan. Adaptive partial differential equation learning for visual saliency detection. In Computer Vision and Pattern Recognition (CVPR), pages 3866–3873, June 2014.
[27] T. Liu, Z. Yuan, J. Sun, J. Wang, N. Zheng, T. X., and S. H.Y. Learning to detect a salient object. IEEE Transactions on Pattern Analysis and Machine Intelligence, 33, 2011.
[28] Y. F. Ma and H. J. Zhang. Contrast-based image attention analysis by using fuzzy growing. In Eleventh ACM International Conference on Multimedia, pages 374–381, 2003.
[29] L. Marchesotti, C. Cifarelli, and G. Csurka. A framework for visual saliency detection with applications to image thumbnailing. In International Conference on Computer Vision (ICCV), pages 2232–2239, 2009.
[30] R. Margolin, A. Tal, and L. Zelnik-Manor. What makes a patch distinct? In Computer Vision and Pattern Recognition (CVPR), pages 1139–1146, June 2013.
[31] J. Pan, Z. Su, M. Bian, and R. Liu. Saliency detection based on an edge-preserving filter. In 2013 20th IEEE International Conference on Image Processing (ICIP), pages 1757–1761, 2013.
[32] F. Perazzi, P. Krähenbühl, Y. Pritch, and A. Hornung. Saliency filters: Contrast based filtering for salient region detection. In Computer Vision and Pattern Recognition (CVPR), pages 733–740, 2012.
[33] Y. Qin, H. Lu, Y. Xu, and H. Wang. Saliency detection via cellular automata. In Computer Vision and Pattern Recognition (CVPR), pages 110–119, 2015.
[34] C. Rother, V. Kolmogorov, and A. Blake. “GrabCut”–Interactive foreground extraction using iterated graph cuts. ACM TOG, 23(3):309–314, 2004.
[35] H. P. S and J. Pujari. Content based image retrieval using color boosted salient points and shape features of an image. International Journal of Image Processing, pages 10–17, 2008.
[36] A. Sharon, G. Meirav, B. Achi, and B. Ronen. Image segmentation by probabilistic bottom-up aggregation and cue integration. IEEE Transactions on Pattern Analysis and Machine Intelligence, 34(2):1–8, 2007.
[37] X. Shen and Y. Wu. A unified approach to salient object detection via low rank matrix recovery. In Computer Vision and Pattern Recognition (CVPR), pages 853–860, June 2012.
[38] B. W. Tatler. The central fixation bias in scene viewing: selecting an optimal viewing position independently of motor biases and image feature distributions. Journal of Vision, 7(14):4.1–17, 2007.
[39] N. Tong, H. Lu, X. Ruan, and M.-H. Yang. Salient object detection via bootstrap learning. In Computer Vision and Pattern Recognition (CVPR), pages 1884–1892, 2015.
[40] J. Van, de Weijer, T. Gevers, and A. D. Bagdanov. Boosting color saliency in image feature detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 28(1):150–156, 2006.
[41] Y. Wei, F. Wen, W. Zhu, and J. Sun. Geodesic saliency using background priors. In European Conference on Computer Vision (ECCV), volume 7574 of Lecture Notes in Computer Science, pages 29–42. Springer Berlin Heidelberg, 2012.
[42] Y. Xie and H. Lu. Visual saliency detection based on bayesian model. In IEEE International Conference on Image Processing (ICIP), pages 645–648, Sept 2011.
[43] Y. Xie, H. Lu, and M.-H. Yang. Bayesian saliency via low and mid level cues. IEEE Transactions on Image Processing, 22(5):1689–1698, May 2013.
[44] Q. Yan, L. Xu, J. Shi, and J. Jia. Hierarchical saliency detection. In Computer Vision and Pattern Recognition(CVPR), pages 1155–1162, June 2013.
[45] C. Yang, L. Zhang, H. Lu, R. Xiang, and M. H. Yang. Saliency detection via graph-based manifold ranking. In Computer Vision and Pattern Recognition (CVPR), pages 3166–3173, 2013.
[46] L. Zhang, Y. Shen, and H. Li. Vsi: A visual saliency-induced index for perceptual image quality assessment. IEEE Transactions on Image Processing, 23(10):4270–4281, Oct 2014.
[47] L. Zhang, M. Tong, T. Marks, H. Shan, and G. Cottrell. SUN: A bayesian framework for saliency using natural statistics. Journal of Vision, 8(7):32:1–20, 2008.
[48] W. Zhu, S. Liang, Y. Wei, and J. Sun. Saliency optimization from robust background detection. In Computer Vision and Pattern Recognition (CVPR), pages 2814–2821, June 2014.

